多层线性模型(Hierarchical Linear Model,HLM)
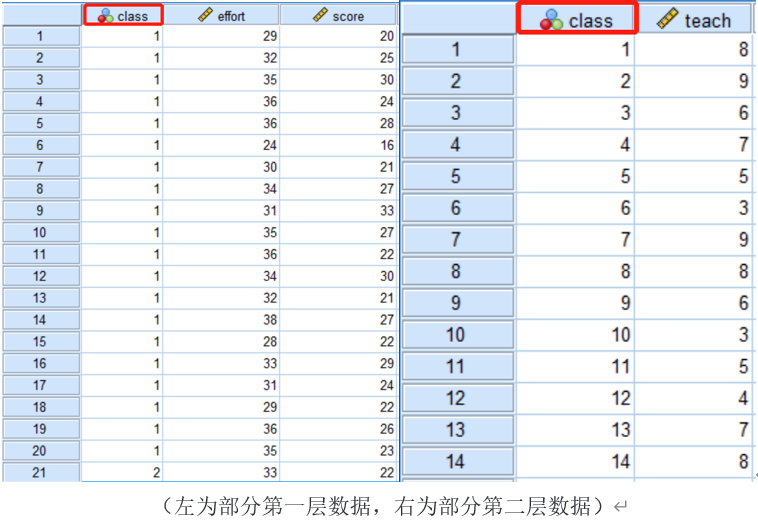
假设某学校有14个班级,每班抽取20个学生进行测试,为第一层测试(Level 1)。另外,测试每个班级的班主任,为第二层测试(Level 2)。传统线性模型只有一层数据,即学生层,因此只能研究学生的情况,如探究学生努力程度对学业成绩的影响。多层线性模型则考虑了班主任的作用,可探究班主任的教学技巧对学生学业成绩的影响,同一个班级的学生之间不独立(均受班主任影响,承认了第一层被试间的相关)。
HLM是最经典的HLM统计工具,最常用到的是两层的线性模型(可用前文提到的例子来理解)。
简单来说,多层线性模型就是线性模型的线性模型,也是回归的回归。要做一个两层线性模型,第一步要分别估计每个群体的回归方程,进行群组间的描述性分析(截距与斜率的平均数及变异数),第二步则要将第一步求得的截距与斜率作为结果变量,与Level 2的变量进行回归分析(虽然从数学上来讲并不是真的分成两个阶段,但这种分法有助于理解HLM)。
那么,具体该如何使用HLM软件分析两层的线性模型呢?
HLM分析流程
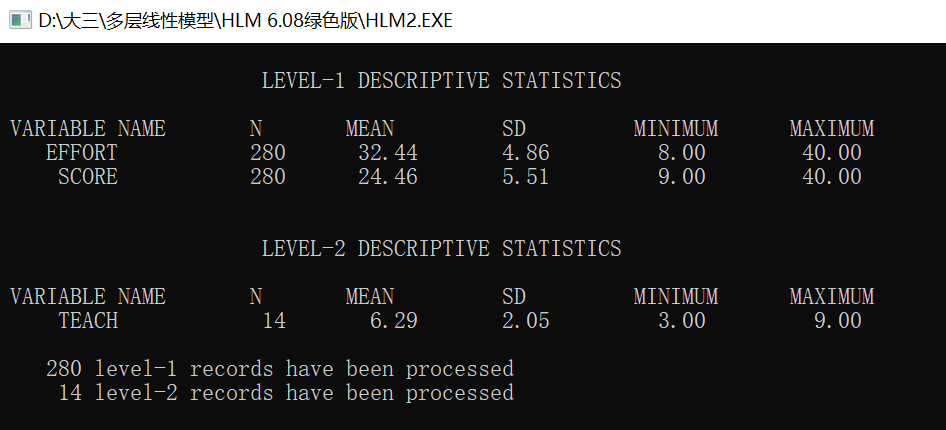
1 资料准备(以SPSS数据为例)
- HLM在不同Level上的数据应放在不同的SPSS数据文件中
- SPSS数据文件的准备工作
- 检查资料
- 缺失值处理(Level 1可以有缺失值,Level 2则不行,也可以在MDM文件中通过设置处理缺失值)
- 使用变量class关联各层的变量数据
- 在HLM中创建MDM文件
双击WHLM.exe打开HLM的主界面,最上面的工具栏即主要菜单。点击File可创建新的HLM/MDM文件。如果已有一份MDM文件,在下次打开的时候可选择Make new MDM from old MDM files导入打开。如果需要新建立一个新的MDM文件,点击Make new MDM file,选择Stata package input。下图为新建MDM文件的示例。
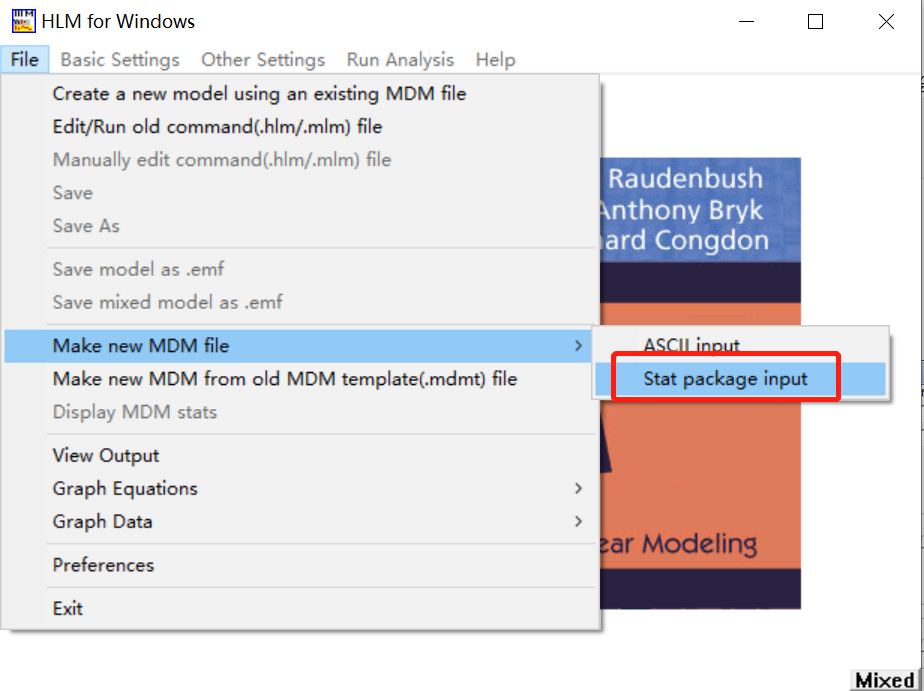
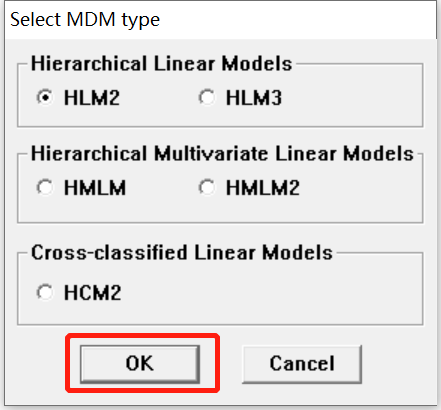
接下来进入选择模型类型的界面。一般使用两层的线性模型,即选择HLM2;同理若数据有3层结构则选择HLM3。若有多个因变量,则可以选择下面的Multivariate。点击OK跳转。
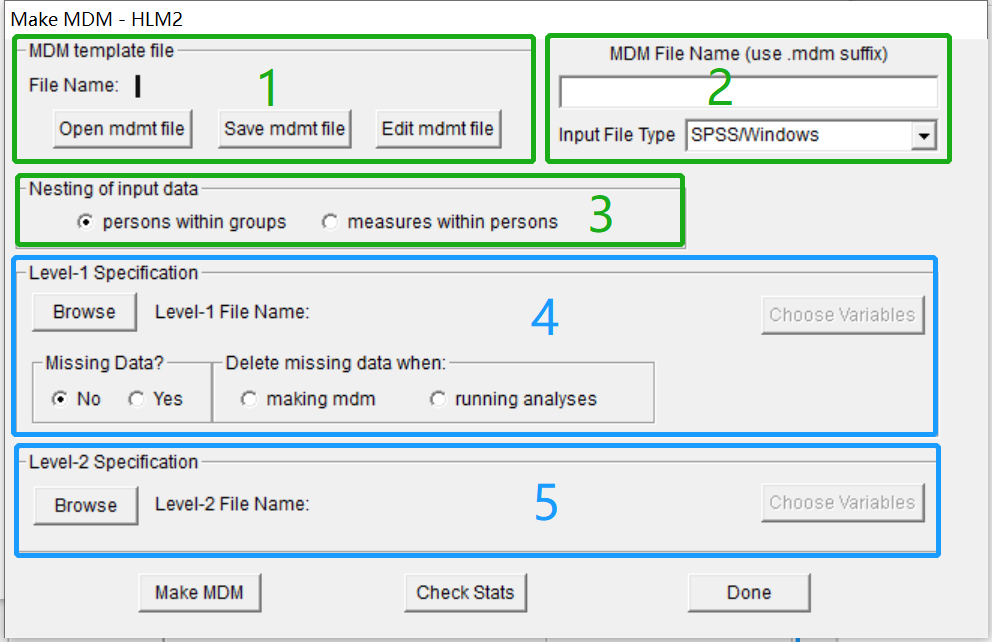
建立文件的界面主要如下图,其中区域1和区域2是MDM文件的名称与保存处。区域3是数据类型的选择,如果数据嵌套在组中,选择第一个persons within groups,如果是追踪测量多个时间点的数据,则选择第二个measures within persons。区域4用于对Level 1的界定,区域5用于对Level 2的界定。
以下是本文所用输入数据的SPSS文件。在这里,Level 1的class和Level 2的class变量名是一样的,且Level 1的class中有很多个数据的数值为1,这就是嵌套的结构,表现为Level 1嵌套在Level 2中。Level 2中可以不包含因变量(本文中为score),但是Level 1中必须有因变量。
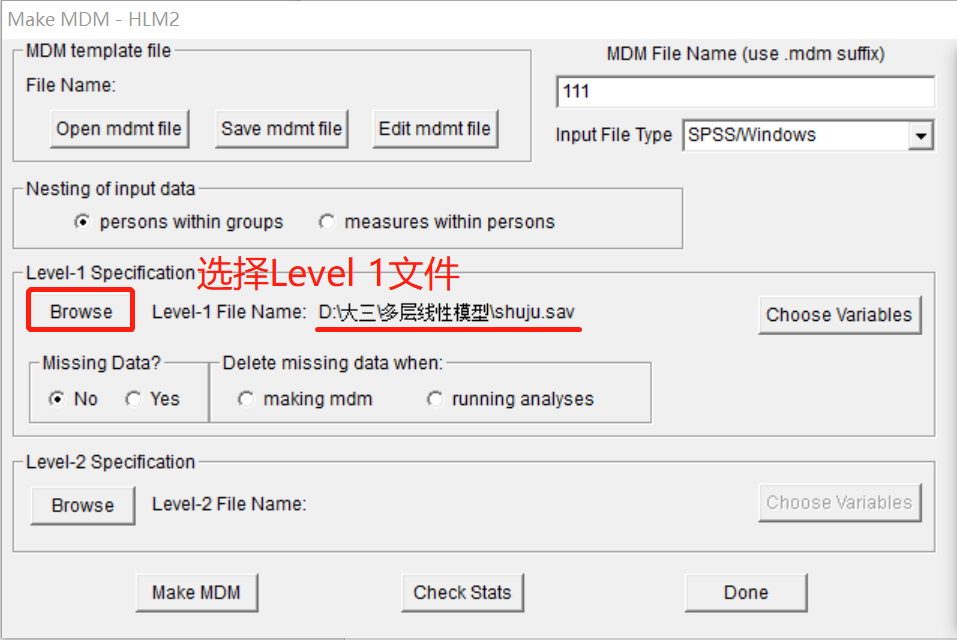
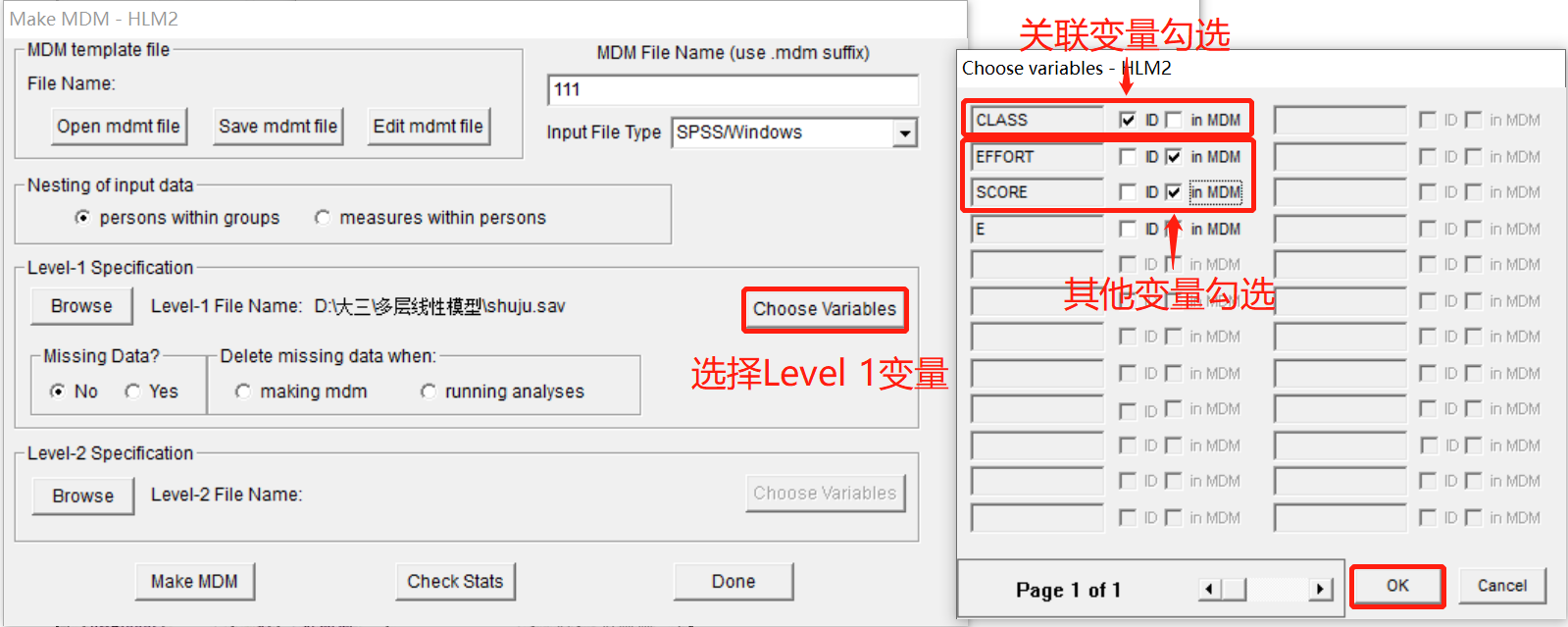
选择已经在SPSS中编辑好的数据,然后分别在区域4和5中界定第一层的变量和第二层的变量。以Level 1为例,点击Browse选择Level 1的SPSS文件,再点击右边Choose Variables选择变量,在这里选择class变量为ID号,其他的两个变量进入Level 1,同理设置Level 2的变量。
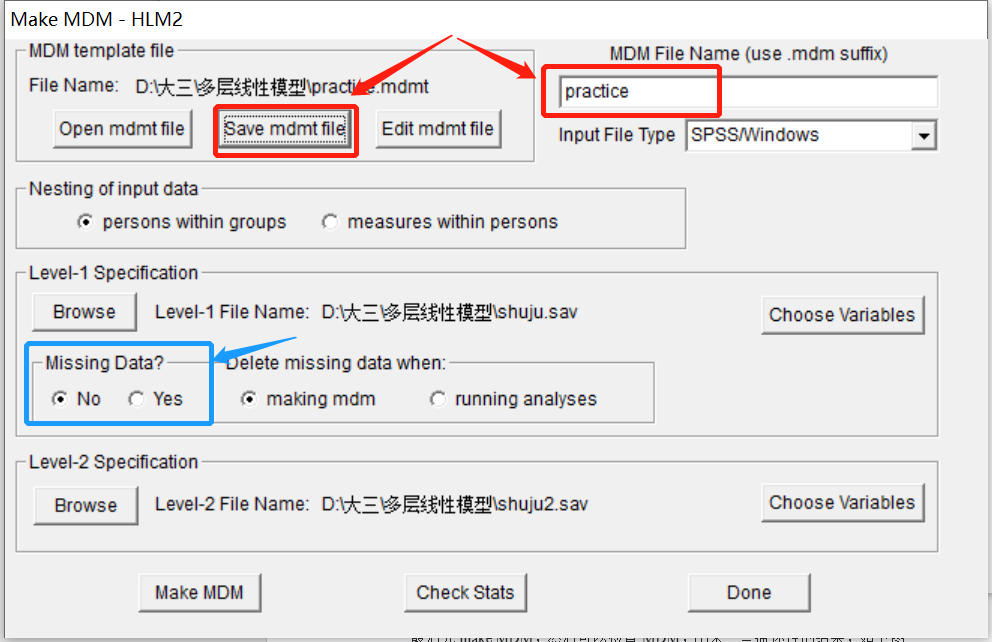
注意如果Level 1数据有缺失值,可勾选区域4的Yes,否则默认勾选No。最后在区域2输入文件名,并点击区域1的Save mdmt file保存文件。
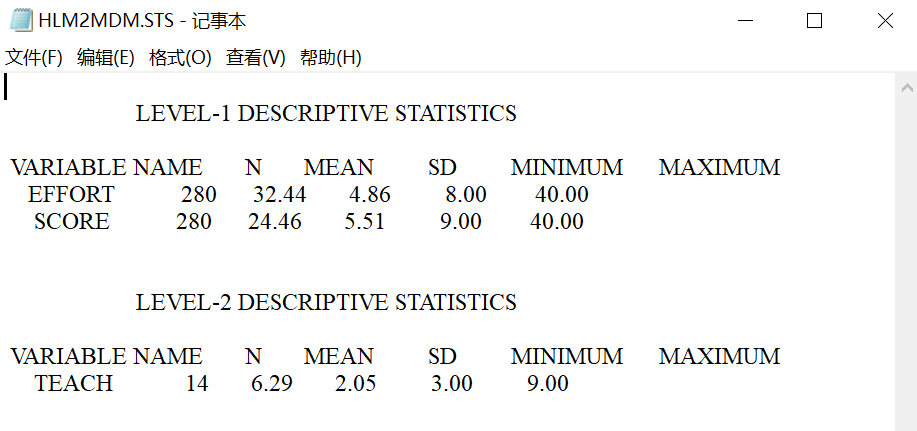
最后点击Make MDM可以检查MDM,显示描述性的结果,点击Check Stats可以将该结果保存在txt文档中。最后点击DONE,进入模型编辑界面。
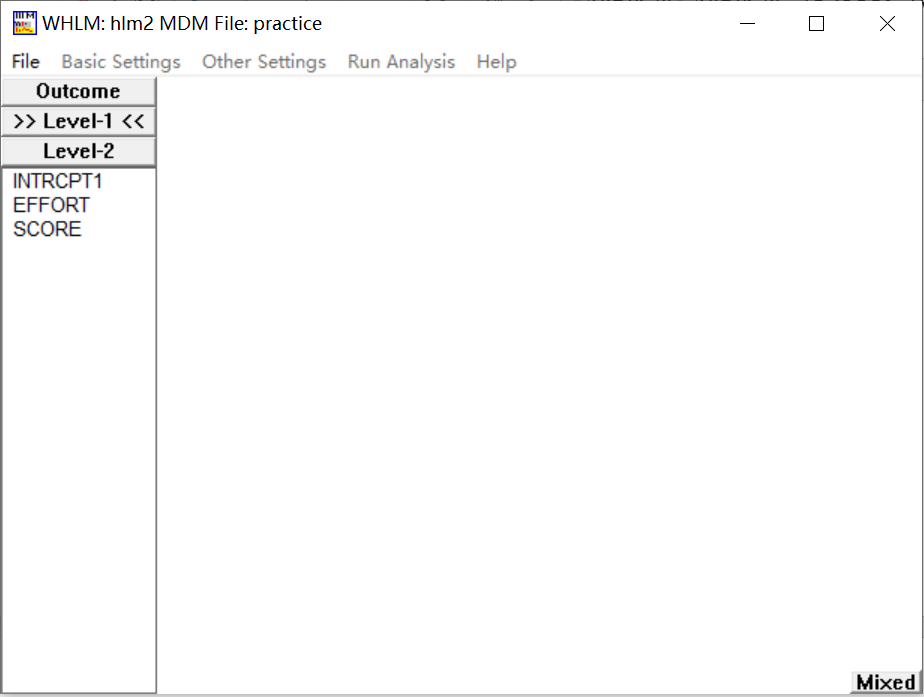
2 模型设置
第一层的数据下包括左下方的所有变量。点击因变量score,将其设定为Outcome variable。
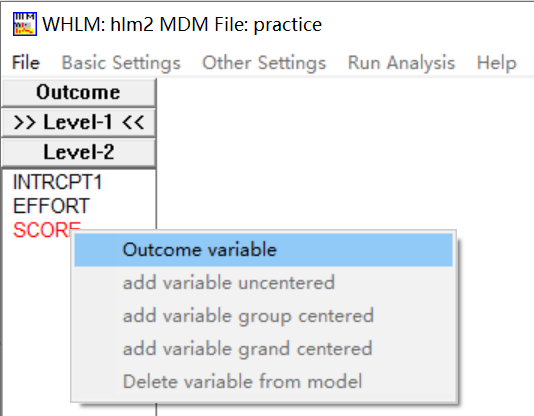
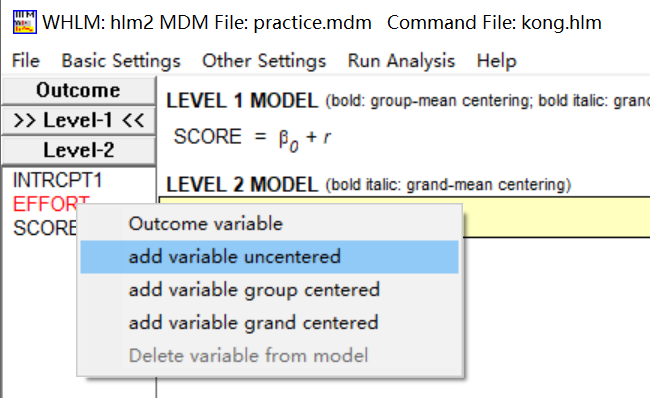
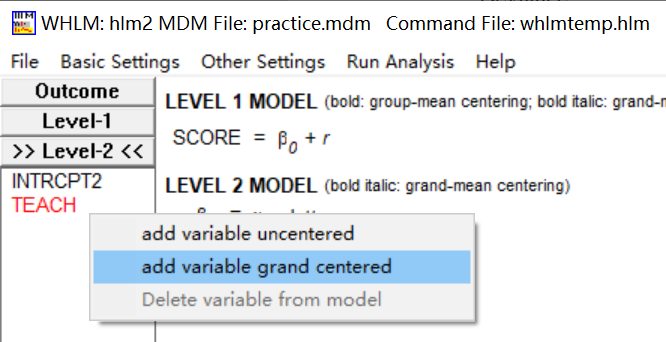
点击自变量发现有三种选项,一种是没有中心化的,一种是组中心化的,一种是总体中心化的数据,根据数据类型进行选择,若是原始数据一般选择没有中心化的选项。
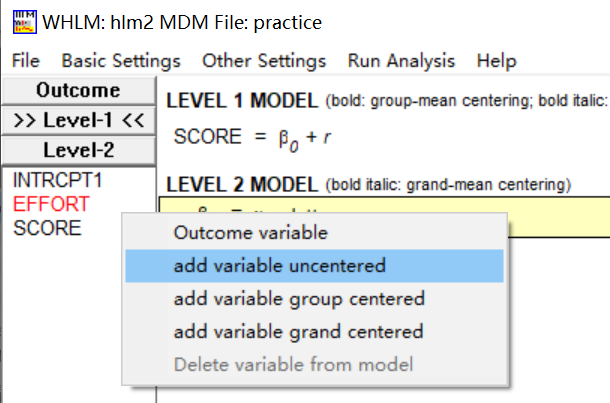
继续设置第二层的变量。完成后就可以运行该程序了。也可以先保存再运行,运行之后的结果默认会以hlm2为文件名的txt文档保存在MDM文件所放置的文件夹中。
3 模型分类
事实上,多层线性模型有四种模型,每种模型的设置方式略有差异:
- 空模型(NULL 或随机ANOVA 模型):计算内生变量的ICC及空模型的组内变异和组间变异,类似于方差分析;
- 随机ANCOVA/系数回归模型:Level 1加入预测变量,计算新的组内变异,了解模型加入预测变量后改善了多少;
- 截距模型:Level 2加入预测变量,计算新的组间变异,了解模型加入预测变量后改善了多少;
- 全模型:评估模型所有的假设,包括Level 1的截距、斜率及Level 2对Level 1的截距及斜率(干扰)估计。
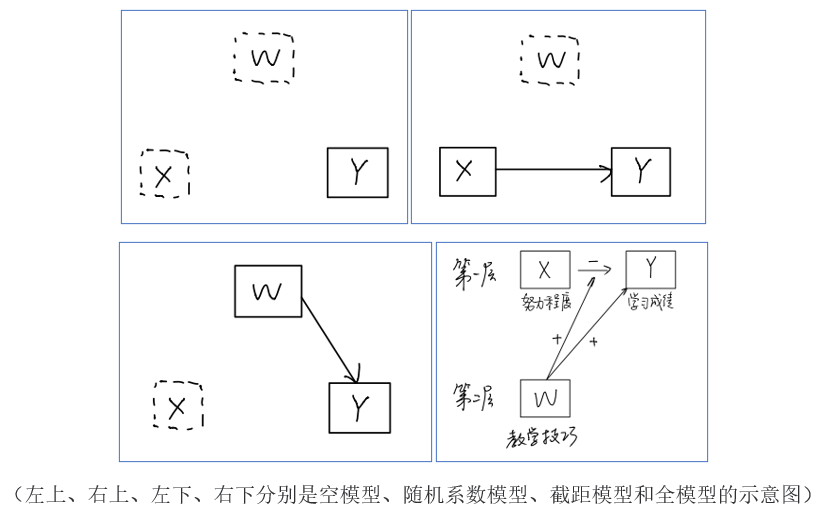
从空模型到全模型可以理解为模型的逐渐完整化,从空模型开始依次检验四个模型,可以较严谨地验证多层线性模型的预测性。 接下来,本文将分别介绍四种模型的模型设置及对应的结果解释,注意四个模型之间具有共通性,可进行整合理解。
HLM模型设置及结果解释
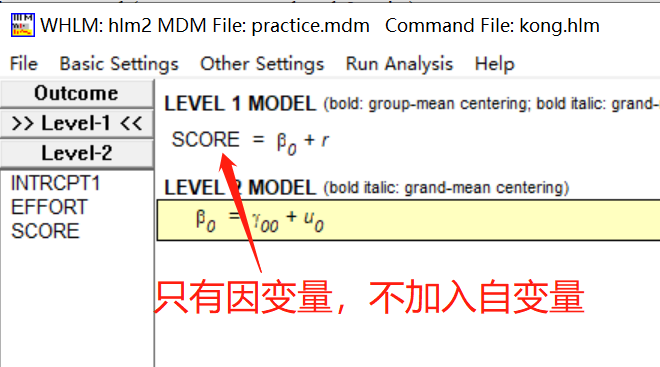
1 空模型
在模型设置阶段,只考虑因变量而不考虑其他变量。保存后,点击File-View Output打开结果txt文档查看输出结果。
输出结果的最开始部分显示所用软件的名称、作者和发行公司、技术支持的联系EMail地址、公司的网址和本次运行的时间等信息。

接下来是对变量的加权情况描述,本次运算没有对参与计算的变量值进行加权处理。同时,模型中的因变量为score。

模型摘要:
$$ICC_1 = \frac{ \tau }{( \tau + \sigma^2)} = \frac{2.4}{2.4+28.1} = 0.079$$


最后给出的是反映当前模型整体拟合程度的似然统计结果和模型中估计的参数个数,供未来把该模型和其他模型进行比较时用。
2 随机ANCOVA/系数回归模型
(1) 随机ANCOVA模型在空模型的基础上,在Level 1加入预测变量。
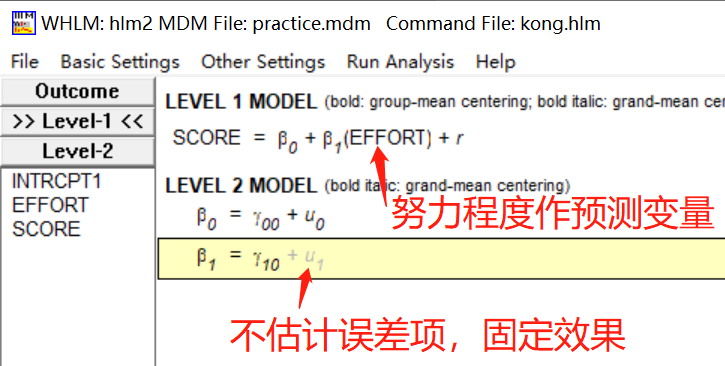
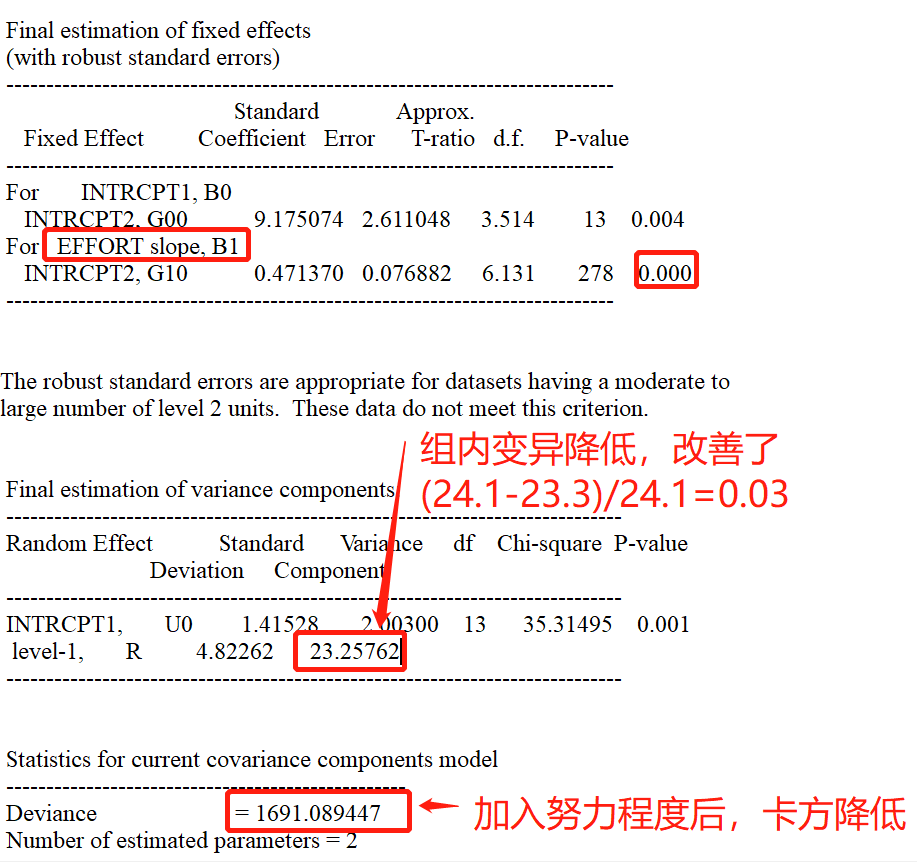
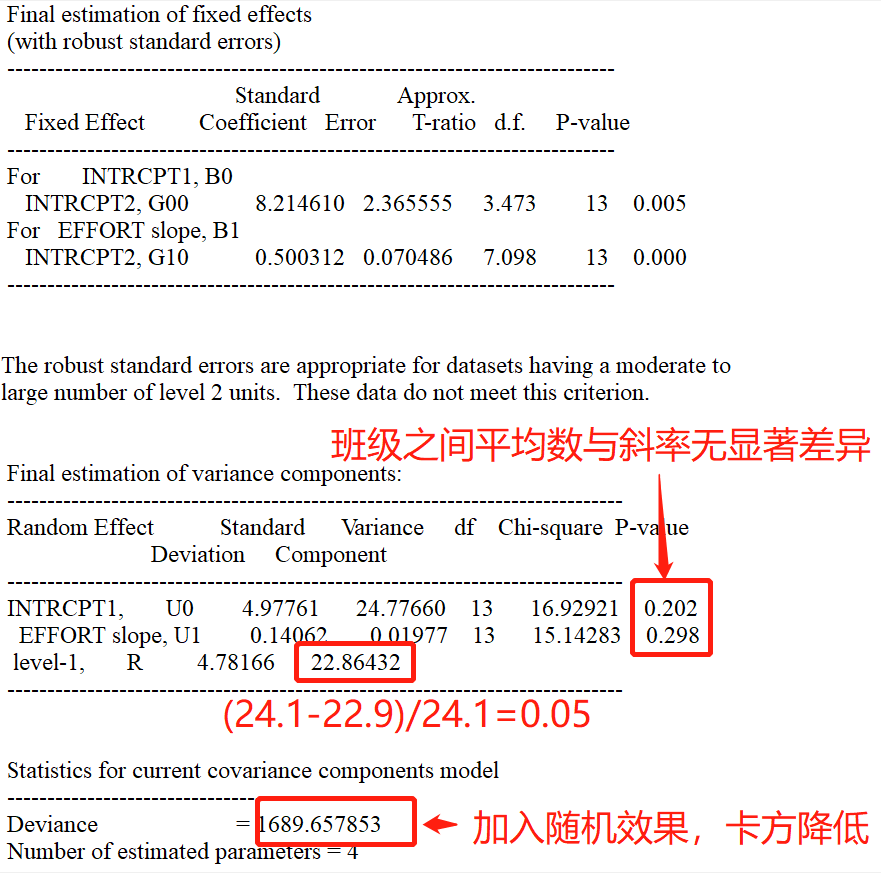

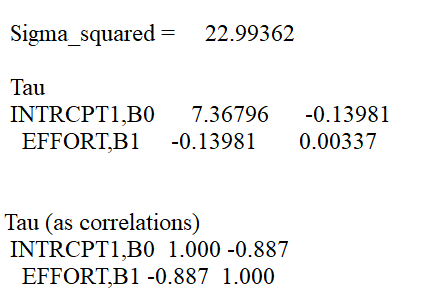
下图呈现的是对模型随机部分的信息描述,当前模型中第一层上的随机变异 $\sigma^2$ ,第二层的变异包括第一层截距和斜率系数在第二层上的变异。分别为协方差矩阵和相关矩阵。
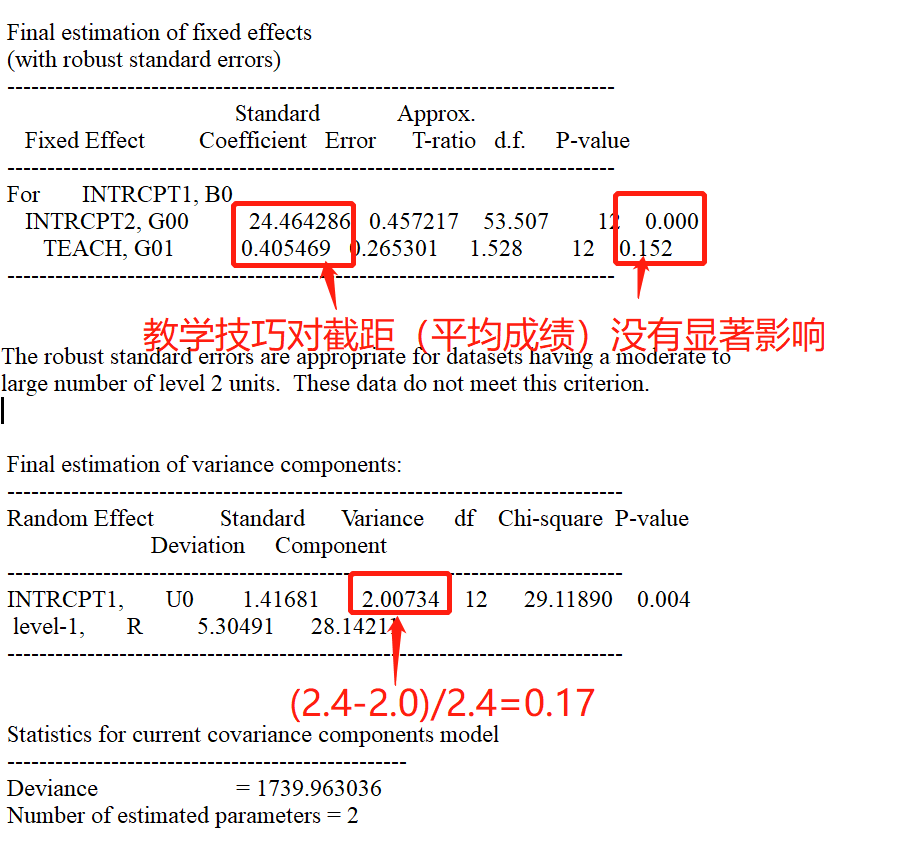
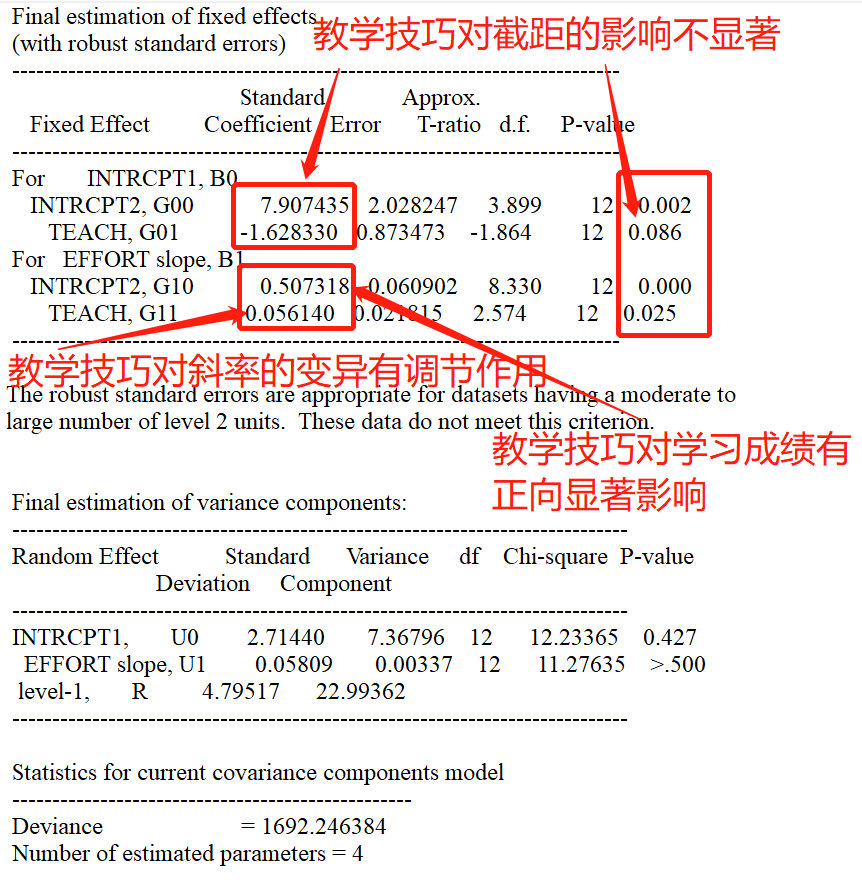
4 全模型
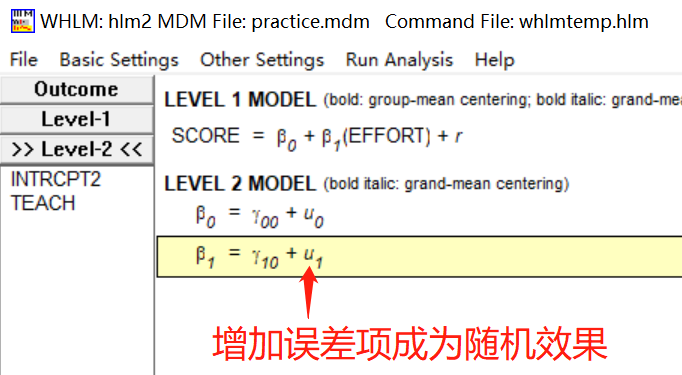
全模型即斜率及截距模型,相当于随机系数模型和截距模型的整合。在Level 1 和 2 中均加入预测变量。

本部分为模型表达式。

下图为对水平1的截距和斜率信度估计的值。

最重要的,是固定部分最后的估计。输出结果有两个,一个是带有稳健的标准误估计(with roubast error),一个没有。本文主要关注前者。